La gráfica de su función de densidad tiene una forma acampanada y es simétrica respecto de un determinado parámetro estadístico. Esta curva se conoce como campana de Gauss y es el gráfico de una función gaussiana.
La importancia de esta distribución radica en que permite modelar numerosos fenómenos naturales, sociales y psicológicos. Mientras que los mecanismos que subyacen a gran parte de este tipo de fenómenos son desconocidos, por la enorme cantidad de variables incontrolables que en ellos intervienen, el uso del modelo normal puede justificarse asumiendo que cada observación se obtiene como la suma de unas pocas causas independientes.
De hecho, la estadística es un modelo matemático que sólo permite describir un fenómeno, sin explicación alguna. Para la explicación causal es preciso el diseño experimental, de ahí que al uso de la estadística en psicología y sociología sea conocido como método correlacional.
La distribución normal también es importante por su relación con la estimación por mínimos cuadrados, uno de los métodos de estimación más simples y antiguos.
Algunos ejemplos de variables asociadas a fenómenos naturales que siguen el modelo de la normal son:
- caracteres morfológicos de individuos como la estatura;
- caracteres fisiológicos como el efecto de un fármaco;
- caracteres sociológicos como el consumo de cierto producto por un mismo grupo de individuos;
- caracteres psicológicos como el cociente intelectual;
- nivel de ruido en telecomunicaciones;
- errores cometidos al medir ciertas magnitudes;
- etc.
En probabilidad, la distribución normal aparece como el límite de varias distribuciones de probabilidad continuas y discretas.
Historia

Laplace usó la distribución normal en el análisis de errores de experimentos. El importante método de mínimos cuadrados fue introducido por Legendre en 1805. Gauss, que afirmaba haber usado el método desde 1794, lo justificó rigurosamente en 1809 asumiendo una distribución normal de los errores. El nombre de Gauss se ha asociado a esta distribución porque la usó con profusión cuando analizaba datos astronómicos y algunos autores le atribuyen un descubrimiento independiente del de De Moivre. Esta atribución del nombre de la distribución a una persona distinta de su primer descubridor es un claro ejemplo de la Ley de Stigler.
El nombre de "campana" viene de Esprit Jouffret que usó el término "bell surface" (superficie campana) por primera vez en 1872 para una distribución normal bivariante de componentes independientes. El nombre de "distribución normal" fue otorgado independientemente por Charles S. Peirce, Francis Galton y Wilhelm Lexis hacia 1875. A pesar de esta terminología, otras distribuciones de probabilidad podrían ser más apropiadas en determinados contextos; véase la discusión sobre ocurrencia, más abajo.
Definición formal
Hay varios modos de definir formalmente una distribución de probabilidad. La forma más visual es mediante su función de densidad. De forma equivalente, también pueden darse para su definición la función de distribución, los momentos, la función característica y la función generatriz de momentos, entre otros.Función de densidad
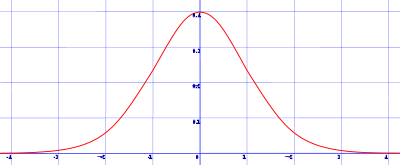

Se llama distribución normal "estándar" a aquélla en la que sus parámetros toman los valores μ = 0 y σ = 1. En este caso la función de densidad tiene la siguiente expresión:

Función de distribución



![\Phi(x)
=\frac{1}{2} \Bigl[ 1 + \operatorname{erf} \Bigl( \frac{x}{\sqrt{2}} \Bigr) \Bigr],
\quad x\in\mathbb{R},](http://upload.wikimedia.org/math/0/4/b/04b42ce6e6eaae4ad68c77d210b9d3ef.png)
![\Phi_{\mu,\sigma^2}(x)
=\frac{1}{2} \Bigl[ 1 + \operatorname{erf} \Bigl( \frac{x-\mu}{\sigma\sqrt{2}} \Bigr) \Bigr],
\quad x\in\mathbb{R}.](http://upload.wikimedia.org/math/1/0/9/1097cbbb6816a7c2e9ce05bdd0ff09d3.png)
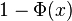 , se denota con frecuencia
, se denota con frecuencia 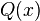 , y es referida, a veces, como simplemente función Q, especialmente en textos de ingeniería.6 7
Esto representa la cola de probabilidad de la distribución gaussiana.
También se usan ocasionalmente otras definiciones de la función Q, las
cuales son todas ellas transformaciones simples de
, y es referida, a veces, como simplemente función Q, especialmente en textos de ingeniería.6 7
Esto representa la cola de probabilidad de la distribución gaussiana.
También se usan ocasionalmente otras definiciones de la función Q, las
cuales son todas ellas transformaciones simples de 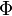 .8
.8La inversa de la función de distribución de la normal estándar (función cuantil) puede expresarse en términos de la inversa de la función de error:


Los valores Φ(x) pueden aproximarse con mucha precisión por distintos métodos, tales como integración numérica, series de Taylor, series asintóticas y fracciones continuas.
Límite inferior y superior estrictos para la función de distribución
Para grandes valores de x la función de distribución de la normal estándar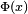 es muy próxima a 1 y
es muy próxima a 1 y  está muy cerca de 0. Los límites elementales
está muy cerca de 0. Los límites elementales
 son útiles.
son útiles.Usando el cambio de variable v = u²/2, el límite superior se obtiene como sigue:

 y la regla del cociente,
y la regla del cociente,
 proporciona el límite inferior.
proporciona el límite inferior.Funciones generadoras
Función generadora de momentos
La función generadora de momentos se define como la esperanza de e(tX). Para una distribución normal, la función generadora de momentos es:![M_X(t) = \mathrm{E} \left[ e^{tX} \right] = \int_{-\infty}^{\infty} \frac{1}{\sigma \sqrt{2\pi} } e^{-\frac{(x - \mu)^2}{2 \sigma^2}} e^{tx} \, dx = e^{\mu t + \frac{\sigma^2 t^2}{2}}](http://upload.wikimedia.org/math/0/8/3/0833056dec593a5766850cf55e4923dd.png)
Función característica
La función característica se define como la esperanza de eitX, donde i es la unidad imaginaria. De este modo, la función característica se obtiene reemplazando t por it en la función generadora de momentos.Para una distribución normal, la función característica es9
![\begin{align}
\chi_X(t;\mu,\sigma) &{} = M_X(i t) = \mathrm{E}
\left[ e^{i t X} \right] \\
&{}=
\int_{-\infty}^{\infty}
\frac{1}{\sigma \sqrt{2\pi}}
e^{- \frac{(x - \mu)^2}{2\sigma^2}}
e^{i t x}
\, dx \\
&{}=
e^{i \mu t - \frac{\sigma^2 t^2}{2}}.
\end{align}](http://upload.wikimedia.org/math/2/6/6/266db4f786e5d21f0dee4788e41cb6fd.png)
Propiedades
Algunas propiedades de la distribución normal son:- Es simétrica respecto de su media, μ;

Distribución de probabilidad alrededor de la media en una distribución N(μ, σ).
- La moda y la mediana son ambas iguales a la media, μ;
- Los puntos de inflexión de la curva se dan para x = μ − σ y x = μ + σ.
- Distribución de probabilidad en un entorno de la media:
- en el intervalo [μ - σ, μ + σ] se encuentra comprendida, aproximadamente, el 68,26% de la distribución;
- en el intervalo [μ - 2σ, μ + 2σ] se encuentra, aproximadamente, el 95,44% de la distribución;
- por su parte, en el intervalo [μ -3σ, μ + 3σ] se encuentra comprendida, aproximadamente, el 99,74% de la distribución. Estas propiedades son de gran utilidad para el establecimiento de intervalos de confianza. Por otra parte, el hecho de que prácticamente la totalidad de la distribución se encuentre a tres desviaciones típicas de la media justifica los límites de las tablas empleadas habitualmente en la normal estándar.
- Si X ~ N(μ, σ2) y a y b son números reales, entonces (aX + b) ~ N(aμ+b, a2σ2).
- Si X ~ N(μx, σx2) e Y ~ N(μy, σy2) son variables aleatorias normales independientes, entonces:
- Su suma está normalmente distribuida con U = X + Y ~ N(μx + μy, σx2 + σy2) (demostración). Recíprocamente, si dos variables aleatorias independientes tienen una suma normalmente distribuida, deben ser normales (Teorema de Crámer).
- Su diferencia está normalmente distribuida con
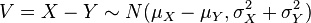 .
. - Si las varianzas de X e Y son iguales, entonces U y V son independientes entre sí.
- La divergencia de Kullback-Leibler,
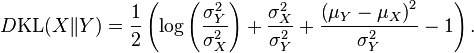
- Si
 e
e 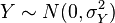 son variables aleatorias independientes normalmente distribuidas, entonces:
son variables aleatorias independientes normalmente distribuidas, entonces:
- Su producto
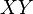 sigue una distribución con densidad
sigue una distribución con densidad  dada por
dada por
 donde
donde  es una función de Bessel modificada de segundo tipo.
es una función de Bessel modificada de segundo tipo.
- Su cociente sigue una distribución de Cauchy con
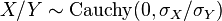 . De este modo la distribución de Cauchy es un tipo especial de distribución cociente.
. De este modo la distribución de Cauchy es un tipo especial de distribución cociente.
- Su producto
- Si
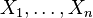 son variables normales estándar independientes, entonces
son variables normales estándar independientes, entonces 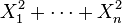 sigue una distribución χ² con n grados de libertad.
sigue una distribución χ² con n grados de libertad. - Si son variables normales estándar independientes, entonces la media muestral
 y la varianza muestral
y la varianza muestral 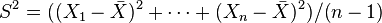 son independientes. Esta propiedad caracteriza a las distribuciones normales y contribuye a explicar por qué el test-F no es robusto respecto a la no-normalidad).
son independientes. Esta propiedad caracteriza a las distribuciones normales y contribuye a explicar por qué el test-F no es robusto respecto a la no-normalidad).
Estandarización de variables aleatorias normales
Como consecuencia de la Propiedad 1; es posible relacionar todas las variables aleatorias normales con la distribución normal estándar.Si
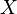 ~
~  , entonces
, entonces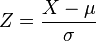
 ~
~  .
.La transformación de una distribución X ~ N(μ, σ) en una N(0, 1) se llama normalización, estandarización o tipificación de la variable X.
Una consecuencia importante de esto es que la función de distribución de una distribución normal es, por consiguiente,

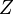 es una distribución normal estándar, ~
es una distribución normal estándar, ~  , entonces
, entonces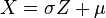
 y varianza
y varianza  .
.La distribución normal estándar está tabulada (habitualmente en la forma de el valor de la función de distribución Φ) y las otras distribuciones normales pueden obtenerse como transformaciones simples, como se describe más arriba, de la distribución estándar. De este modo se pueden usar los valores tabulados de la función de distribución normal estándar para encontrar valores de la función de distribución de cualquier otra distribución normal.
Momentos
Los primeros momentos de la distribución normal son:| Número | Momento | Momento central | Cumulante |
|---|---|---|---|
| 0 | 1 | 1 | |
| 1 |  |
0 | |
| 2 |  |
 |
|
| 3 | 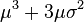 |
0 | 0 |
| 4 | 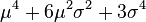 |
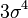 |
0 |
| 5 |  |
0 | 0 |
| 6 | 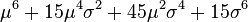 |
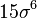 |
0 |
| 7 |  |
0 | 0 |
| 8 |  |
 |
0 |
Los momentos centrales de orden superior (2k con μ = 0) vienen dados por la fórmula
![E\left[X^{2k}\right]=\frac{(2k)!}{2^k k!} \sigma^{2k}.](http://upload.wikimedia.org/math/9/e/e/9ee2fb62550523bac223697b7ad104b0.png)
El Teorema del Límite Central
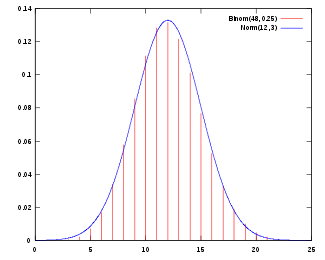
La importancia práctica del Teorema del límite central es que la función de distribución de la normal puede usarse como aproximación de algunas otras funciones de distribución. Por ejemplo:
- Una distribución binomial de parámetros n y p es aproximadamente normal para grandes valores de n, y p no demasiado cercano a 1 ó 0 (algunos libros recomiendan usar esta aproximación sólo si np y n(1 − p) son ambos, al menos, 5; en este caso se debería aplicar una corrección de continuidad).
La normal aproximada tiene parámetros μ = np, σ2 = np(1 − p).
- Una distribución de Poisson con parámetro λ es aproximadamente normal para grandes valores de λ.
La distribución normal aproximada tiene parámetros μ = σ2 = λ.
Divisibilidad infinita
Las normales tienen una distribución de probabilidad infinitamente divisible: Para una distribución normal X de media μ y varianza σ2 ≥ 0, es posible encontrar n variables aleatorias independientes {X1,...,Xn} cada una con distribución normal de media μ/n y varianza σ2/n dado que la suma X1 + . . . + Xn de estas n variables aleatorias
Estabilidad
Las distribuciones normales son estrictamente estables.Desviación típica e intervalos de confianza
Alrededor del 68% de los valores de una distribución normal están a una distancia σ < 1 (desviación típica) de la media, μ; alrededor del 95% de los valores están a dos desviaciones típicas de la media y alrededor del 99,7% están a tres desviaciones típicas de la media. Esto se conoce como la "regla 68-95-99,7" o la "regla empírica".Para ser más precisos, el área bajo la curva campana entre μ − nσ y μ + nσ en términos de la función de distribución normal viene dada por

 |
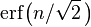 |
|---|---|
| 1 | 0,682689492137 |
| 2 | 0,954499736104 |
| 3 | 0,997300203937 |
| 4 | 0,999936657516 |
| 5 | 0,999999426697 |
| 6 | 0,999999998027 |
 |
|
|---|---|
| 0,80 | 1,28155 |
| 0,90 | 1,64485 |
| 0,95 | 1,95996 |
| 0,98 | 2,32635 |
| 0,99 | 2,57583 |
| 0,995 | 2,80703 |
| 0,998 | 3,09023 |
| 0,999 | 3,29052 |
| 0,9999 | 3,8906 |
| 0,99999 | 4,4172 |
Forma familia exponencial
La distribución normal tiene forma de familia exponencial biparamétrica con dos parámetros naturales, μ y 1/σ2, y estadísticos naturales X y X2. La forma canónica tiene como parámetros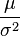 y
y  y estadísticos suficientes
y estadísticos suficientes 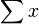 y
y 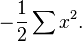
Distribución normal compleja
Considérese la variable aleatoria compleja gaussiana
 . La función de distribución de la variable conjunta es entonces
. La función de distribución de la variable conjunta es entonces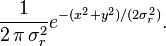
 , la función de distribución resultante para la variable gaussiana compleja Z es
, la función de distribución resultante para la variable gaussiana compleja Z es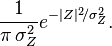
Distribuciones relacionadas
 es una distribución de Rayleigh si
es una distribución de Rayleigh si 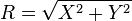 donde
donde  y
y  son dos distribuciones normales independientes.
son dos distribuciones normales independientes.
 es una distribución χ² con
es una distribución χ² con 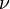 grados de libertad si
grados de libertad si  donde
donde  para
para  y son independientes.
y son independientes.
 es una distribución de Cauchy si
es una distribución de Cauchy si  para
para  y
y  son dos distribuciones normales independientes.
son dos distribuciones normales independientes.
 es una distribución log-normal si
es una distribución log-normal si  y
y 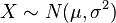 .
.
- Relación con una distribución estable: si
 entonces .
entonces .
- Distribución normal truncada. si
 entonces truncando X por debajo de
entonces truncando X por debajo de  y por encima de
y por encima de  dará lugar a una variable aleatoria de media
dará lugar a una variable aleatoria de media  donde
donde 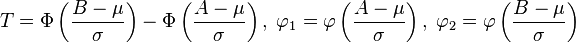 y
y 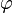 es la función de densidad de una variable normal estándar.
es la función de densidad de una variable normal estándar.
- Si es una variable aleatoria normalmente distribuida e
 , entonces
, entonces  tiene una distribución normal doblada.
tiene una distribución normal doblada.
Estadística descriptiva e inferencial
Resultados
De la distribución normal se derivan muchos resultados, incluyendo rangos de percentiles ("percentiles" o "cuantiles"), curvas normales equivalentes, stanines, z-scores, y T-scores. Además, un número de procedimientos de estadísticos de comportamiento están basados en la asunción de que esos resultados están normalmente distribuidos. Por ejemplo, el test de Student y el análisis de varianza (ANOVA) (véase más abajo). La gradación de la curva campana asigna grados relativos basados en una distribución normal de resultados.Tests de normalidad
Los tests de normalidad se aplican a conjuntos de datos para determinar su similitud con una distribución normal. La hipótesis nula es, en estos casos, si el conjunto de datos es similar a una distribución normal, por lo que un P-valor suficientemente pequeño indica datos no normales.- Prueba de Kolmogórov-Smirnov
- Test de Lilliefors
- Test de Anderson–Darling
- Test de Ryan–Joiner
- Test de Shapiro–Wilk
- Normal probability plot (rankit plot)
- Test de Jarque–Bera
- Test omnibús de Spiegelhalter
Estimación de parámetros
Estimación de parámetros de máxima verosimilitud
Véase también: Máxima verosimilitud.
Supóngase que
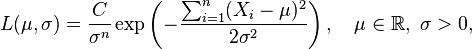
En el método de máxima verosimilitud, los valores de μ y σ que maximizan la función de verosimilitud se toman como estimadores de los parámetros poblacionales μ y σ.
Habitualmente en la maximización de una función de dos variables, se podrían considerar derivadas parciales. Pero aquí se explota el hecho de que el valor de μ que maximiza la función de verosimilitud con σ fijo no depende de σ. No obstante, encontramos que ese valor de μ, entonces se sustituye por μ en la función de verosimilitud y finalmente encontramos el valor de σ que maximiza la expresión resultante.
Es evidente que la función de verosimilitud es una función decreciente de la suma
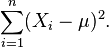
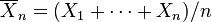
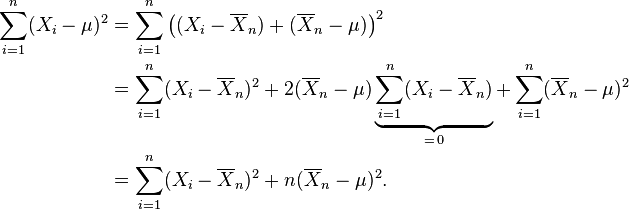


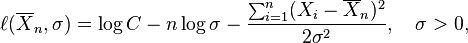
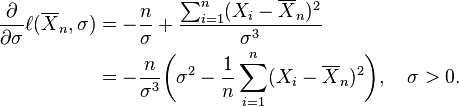

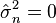 por esta fórmula, refleja el hecho de que en estos casos la función de verosimilitud es ilimitada cuando σ decrece hasta cero.)
por esta fórmula, refleja el hecho de que en estos casos la función de verosimilitud es ilimitada cuando σ decrece hasta cero.)Consecuentemente esta media de cuadrados de residuos es el estimador de máxima verosimilitud de σ2, y su raíz cuadrada es el estimador de máxima verosimilitud de σ basado en las n observaciones. Este estimador
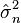 es sesgado, pero tiene un menor error medio al cuadrado que el habitual estimador insesgado, que es n/(n − 1) veces este estimador.
es sesgado, pero tiene un menor error medio al cuadrado que el habitual estimador insesgado, que es n/(n − 1) veces este estimador.Sorprendente generalización
La derivada del estimador de máxima verosimilitud de la matriz de covarianza de una distribución normal multivariante es despreciable. Involucra el teorema espectral y la razón por la que puede ser mejor para ver un escalar como la traza de una matriz 1×1 que como un mero escalar. Véase estimación de la covarianza de matrices.Estimación insesgada de parámetros
El estimador de máxima verosimilitud de la media poblacional μ, es un estimador insesgado de la media poblacional.
de máxima verosimilitud de la media poblacional μ, es un estimador insesgado de la media poblacional.El estimador de máxima verosimilitud de la varianza es insesgado si asumimos que la media de la población es conocida a priori, pero en la práctica esto no ocurre. Cuando disponemos de una muestra y no sabemos nada de la media o la varianza de la población de la que se ha extraído, como se asumía en la derivada de máxima verosimilitud de arriba, entonces el estimador de máxima verosimilitud de la varianza es sesgado. Un estimador insesgado de la varianza σ2 es la cuasi varianza muestral:


 y varianza
y varianza 
La estimación de máxima verosimilitud de la desviación típica es la raíz cuadrada de la estimación de máxima verosimilitud de la varianza. No obstante, ni ésta, ni la raíz cuadrada de la cuasivarianza muestral proporcionan un estimador insesgado para la desviación típica (véase estimación insesgada de la desviación típica para una fórmula particular para la distribución normal.
Incidencia
Las distribuciones aproximadamente normales aparecen por doquier, como queda explicado por el teorema central del límite. Cuando en un fenómeno se sospecha la presencia de un gran número de pequeñas causas actuando de forma aditiva e independiente es razonable pensar que las observaciones serán "normales". Hay métodos estadísticos para probar empíricamente esta asunción, por ejemplo, el test de Kolmogorov-Smirnov.Hay causas que pueden actuar de forma multiplicativa (más que aditiva). En este caso, la asunción de normalidad no está justificada y es el logaritmo de la variable en cuestión el que estaría normalmente distribuido. La distribución de las variables directamente observadas en este caso se denomina log-normal.
Finalmente, si hay una simple influencia externa que tiene un gran efecto en la variable en consideración, la asunción de normalidad no está tampoco justificada. Esto es cierto incluso si, cuando la variable externa se mantiene constante, las distribuciones marginales resultantes son, en efecto, normales. La distribución completa será una superposición de variables normales, que no es en general normal. Ello está relacionado con la teoría de errores (véase más abajo).
A continuación se muestran una lista de situaciones que estarían, aproximadamente, normalmente distribuidas. Más abajo puede encontrarse una discusión detallada de cada una de ellas:
- En problemas de recuento, donde el teorema central del límite
incluye una aproximación de discreta a continua y donde las
distribuciones infinitamente divisibles y descomponibles están involucradas, tales como:
- variables aleatorias binomiales, asociadas con preguntas sí/no;
- variables aleatorias de Poisson, asociadas con eventos raros;
- En medidas fisiológicas de especímenes biológicos:
- El logaritmo de las medidas del tamaño de tejidos vivos (longitud, altura, superficie de piel, peso);
- La longitud de apéndices inertes (pelo, garras, rabos, dientes) de especímenes biológicos en la dirección del crecimento;
- Otras medidas fisiológicas podrían estar normalmente distribuidas, aunque no hay razón para esperarlo a priori;
- Se asume con frecuencia que los errores de medida están normalmente distribuidos y cualquier desviación de la normalidad se considera una cuestión que debería explicarse;
- Variables financieras, en el modelo Black-Scholes:
- Cambios en el logaritmo de
-
- Mientras que el modelo Black-Scholes presupone normalidad, en realidad estas variables exhiben colas pesadas, como puede verse en crash de las existencias de mercado;
- Otras variables financieras podrían estar normalmente distribuidas, pero no hay razón para esperarlo a priori;
- Intensidad de la luz:
- La intensidad de la luz láser está normalmente distribuida;
- La luz térmica tiene una distribución de Bose-Einstein en escalas de tiempo muy breves y una distribución normal en grandes escalas de tiempo debido al teorema central del límite.
Recuento de fotones
La intensidad de la luz de una sola fuente varía con el tiempo, así como las fluctuaciones térmicas que pueden observarse si la luz se analiza a una resolución suficientemente alta. La mecánica cuántica interpreta las medidas de la intensidad de la luz como un recuento de fotones, donde la asunción natural es usar la distribución de Poisson. Cuando la intensidad de la luz se integra a lo largo de grandes periodos de tiempo mayores que el tiempo de coherencia, la aproximación Poisson - Normal es apropiada.Medida de errores
La normalidad es la asunción central de la teoría matemática de errores. De forma similar en el ajuste de modelos estadístico, un indicador de la bondad del ajuste es que el error residual (así es como se llaman los errores en esta circunstancia) sea independiente y normalmente distribuido. La asunción es que cualquier desviación de la normalidad necesita ser explicada. En ese sentido, en ambos, ajuste de modelos y teoría de errores, la normalidad es la única observación que no necesita ser explicada, sino que es esperada. No obstante, si los datos originales no están normalmente distribuidos (por ejemplo, si siguen una distribución de Cauchy, entonces los residuos tampoco estarán normalmente distribuidos. Este hecho es ignorado habitualmente en la práctica.Las medidas repetidas de la misma cantidad se espera que cedan el paso a resultados que están agrupados entorno a un valor particular. Si todas las fuentes principales de errores se han tomado en cuenta, se asume que el error que queda debe ser el resultado de un gran número de muy pequeños y aditivos efectos y, por consiguiente, normal. Las desviaciones de la normalidad se interpretan como indicaciones de errores sistemáticos que no han sido tomados en cuenta. Puede debatirse si esta asunción es válida.
Una famosa observación atribuida a Gabriel Lippmann dice:
Todo el mundo cree en la ley normal de los errores: los matemáticos, porque piensan que es un hecho experimental; y los experimentadores, porque suponen que es un teorema matemáticoOtra fuente podría ser Henri Poincaré.
Características físicas de especímenes biológicos
Los tamaños de los animales adultos siguen aproximadamente una distribución log-normal. La evidencia y explicación basada en modelos de crecimiento fue publicada por primera vez en el libro Problemas de crecimiento relativo, de 1932, por Julian Huxley.Las diferencias de tamaño debido a dimorfismos sexuales u otros polimorfismos de insectos, como la división social de las abejas en obreras, zánganos y reinas, por ejemplo, hace que la distribución de tamaños se desvíe hacia la lognormalidad.
La asunción de que el tamaño lineal de los especímenes biológicos es normal (más que lognormal) nos lleva a una distribución no normal del peso (puesto que el peso o el volumen es proporcional al cuadrado o el cubo de la longitud y las distribuciones gaussianas sólo mantienen las transformaciones lineales). A la inversa, asumir que el peso sigue una distribución normal implica longitudes no normales. Esto es un problema porque, a priori, no hay razón por la que cualquiera de ellas (longitud, masa corporal u otras) debería estar normalmente distribuida. Las distribuciones lognormales, por otro lado, se mantienen entre potencias, así que el "problema" se desvanece si se asume la lognormalidad.
Por otra parte, hay algunas medidas biológicas donde se asume normalidad, tales como la presión sanguínea en humanos adultos. Esta asunción sólo es posible tras separar a hombres y mujeres en distintas poblaciones, cada una de las cuales está normalmente distribuida.
Variables financieras

No obstante, en realidad las variables financieras exhiben colas pesadas y así, la asunción de normalidad infravalora la probabilidad de eventos extremos como quiebras financieras. Se han sugerido correcciones a este modelo por parte de matemáticos como Benoît Mandelbrot, quien observó que los cambios en el logaritmo durante breves periodos de tiempo (como un día) se aproximan bien por distribuciones que no tienen una varianza finita y, por consiguiente, el teorema central del límite no puede aplicarse. Más aún, la suma de muchos de tales cambios sigue una distribución de log-Levy.
Distribuciones en tests de inteligencia
A veces, la dificultad y número de preguntas en un test de inteligencia se selecciona de modo que proporcionen resultados normalmente distribuidos. Más aún, las puntuaciones "en crudo" se convierten a valores que marcan el cociente intelectual ajustándolas a la distribución normal. En cualquier caso se trata de un resultado causado deliberadamente por la construcción del test o de una interpretación de las puntuaciones que sugiere normalidad para la mayoría de la población. Sin embargo, la cuestión acerca de si la inteligencia en sí está normalmente distribuida es más complicada porque se trata de una variable latente y, por consiguiente, no puede observarse directamente.Ecuación de difusión
La función de densidad de la distribución normal está estrechamente relacionada con la ecuación de difusión (homogénea e isótropa) y, por tanto, también con la ecuación de calor. Esta ecuación diferencial parcial describe el tiempo de evolución de una función de densidad bajo difusión. En particular, la función de densidad de masa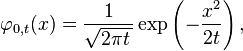

Más generalmente, si la densidad de masa inicial viene dada por una función φ(x), entonces la densidad de masa en un tiempo t vendrá dada por la convolución de φ y una función de densidad normal.
Uso en estadística computacional
Generación de valores para una variable aleatoria normal
Para simulaciones por ordenador es útil, en ocasiones, generar valores que podrían seguir una distribución normal. Hay varios métodos y el más básico de ellos es invertir la función de distribución de la normal estándar. Se conocen otros métodos más eficientes, uno de los cuales es la transformación de Box-Muller. Un algoritmo incluso más rápido es el algoritmo zigurat. Ambos se discuten más abajo. Una aproximación simple a estos métodos es programarlos como sigue: simplemente súmense 12 desviaciones uniformes (0,1) y réstense 6 (la mitad de 12). Esto es bastante útil en muchas aplicaciones. La suma de esos 12 valores sigue la distribución de Irwin-Hall; son elegidos 12 para dar a la suma una varianza de uno, exactamente. Las desviaciones aleatorias resultantes están limitadas al rango (−6, 6) y tienen una densidad que es una doceava sección de una aproximación polinomial de undécimo orden a la distribución normal .El método de Box-Muller dice que, si tienes dos números aleatorios U y V uniformemente distribuidos en (0, 1], (por ejemplo, la salida de un generador de números aleatorios), entonces X e Y son dos variables aleatorias estándar normalmente distribuidas, donde:

Un método mucho más rápido que la transformación de Box-Muller, pero que sigue siendo exacto es el llamado algoritmo Zigurat, desarrollado por George Marsaglia. En alrededor del 97% de los casos usa sólo dos números aleatorios, un entero aleatorio y un uniforme aleatorio, una multiplicación y un test-si . Sólo un 3% de los casos donde la combinación de estos dos cae fuera del "corazón del zigurat", un tipo de rechazo muestral usando logaritmos, exponenciales y números aleatorios más uniformes deberían ser empleados.
Hay también alguna investigación sobre la conexión entre la rápida transformación de Hadamard y la distribución normal, en virtud de que la transformación emplea sólo adición y sustracción y por el teorema central del límite los números aleatorios de casi cualquier distribución serán transformados en la distribución normal. En esta visión se pueden combinar una serie de transformaciones de Hadamard con permutaciones aleatorias para devolver conjuntos de datos aleatorios normalmente distribuidos.
Aproximaciones numéricas de la distribución normal y su función de distribución
La función de distribución normal se usa extensamente en computación científica y estadística. Por consiguiente, ha sido implementada de varias formas.Abramowitz y Stegun (1964) dan la conocida como "mejor aproximación de Hastings" para Φ(x) con x > 0 con un error absoluto |ε(x)| < 7.5·10−8 (algoritmo 26.2.17):


La Biblioteca Científica GNU calcula valores de la función de distribución normal estándar usando aproximaciones por funciones racionales a trozos. Otro método de aproximación usa polinomios de tercer grado en intervalos. El artículo sobre el lenguaje de programación bc proporciona un ejemplo de cómo computar la función de distribución en GNU bc.
Para una discusión más detallada sobre cómo calcular la distribución normal, véase la sección 3.4.1C. de The Art of Computer Programming (El arte de la programación por ordenador), de Knuth.